




在這個生成式 AI 爆發的時代,要蓋 AI 資料中心,電力幾乎等於入場門票,但拿到電,不代表就能把算力塞滿。 生成式 AI 把單櫃功耗與熱密度一路推高,下一個很快浮上檯面的瓶頸是散熱跟不上,等於把好不容易搶來的電白白浪費掉。
早先曾提到「沒有電就沒有選址的討論空間」,但更進一步應該要討論的是,在電力吃緊已成常態後,資料中心如何透過液冷等技術,把同樣的供電換成更多有效算力。
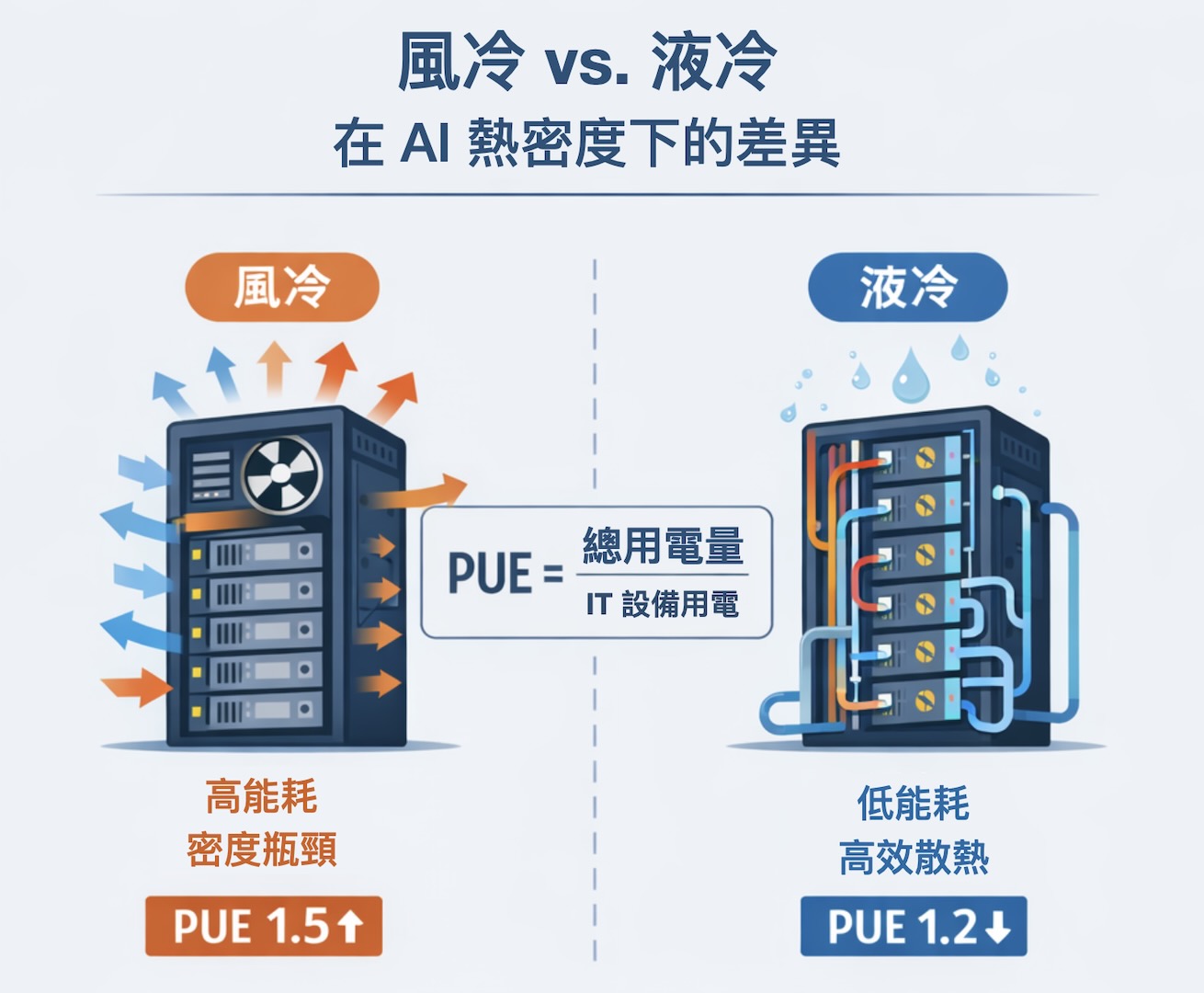
AI 把用電推向極限,風冷先撞上密度天花板
傳統資料中心主要靠風冷,也就是透過空調、氣流管理、冷熱通道與機內風扇,把伺服器產生的熱往外丟。 在過去十多 kW/櫃的時代,這一套運作得還算穩定,但生成式 AI 帶來的不是多幾台伺服器這麼簡單,而是單櫃功耗和單點熱量的暴衝。
當機櫃功耗從十多 kW 走向數十 kW、甚至朝百 kW 以上邁進時,多數資料中心會遇到兩個現實:第一,冷卻用電急速增加,空調得加大噸數、風扇轉得更快,冷卻本身變成一個巨大的電力黑洞;第二,佈建受到限制,熱排不掉,機櫃就得降規上架或被迫分散部署,就算 GPU 到了、電也談下來,算力卻上不去。 實務上,風冷在 20~30 kW/櫃附近就開始吃力,風扇與空調能耗會隨熱密度急遽放大,讓整體 PUE(Power Usage Effectiveness,能源使用效率)卡在 1.5 上下,很難再往下壓。
這也是為什麼,散熱這幾年從機電配套被拉進算力工程的範疇,散熱效率其實就是算力效率的一部分,誰能把熱處理好,誰就能在同樣供電條件下塞進更多 GPU。
 (Source:科技新報整理)
(Source:科技新報整理)
PUE:電有沒有花在算力刀口上
談資料中心省電,最常被提起的指標是 PUE。PUE = 資料中心總用電 / IT 設備用電 。
分母裡的「IT 用電」,是伺服器、網通、儲存等真正拿來做運算的耗電;分子裡的「總用電」,則再加上空調與冷卻系統、供配電轉換損失、照明與管理系統等非 IT 負載。 PUE 越接近 1,代表越多電真的花在算力上,而不是花在讓這些機器能勉強跑起來的部分。
以業界統計來看,多數資料中心 PUE 仍落在 1.4–1.6,意味著每 1 kW 的 IT 負載,還要額外再花 0.4~0.6 kW 在冷卻與供電等基礎設施上;只有少數頂級的超大規模據點,才把 PUE 壓到 1.1~1.2,甚至更低。 生成式 AI 把熱密度推上新高,往往也意味著冷卻用電佔比直線上升,把整體 PUE 往上拉,讓「搶來的電」有更大一塊被浪費在空調上。
在這裡,液冷扮演的角色就很直接,用熱傳效率更高的方式,把熱從 GPU 和 CPU 身上帶走,降低冷卻系統本身的用電,讓更多電回流到 IT 負載,PUE 才有機會從 1.5 往 1.2、甚至更接近 1.1 靠攏。
液冷從加分題變成必修
其實液冷並不是新技術,但在 AI 世代,它從少數玩家採用的加分題,變成高密度 AI 機房幾乎必備的標配,關鍵原因在於,液體的熱傳導效率遠高於空氣,更適合處理單點功耗極高、熱密度極端集中的情境。
業界常見的液冷路線,大致可以分成兩種:
- 直觸式液冷(Direct‑to‑Chip):讓冷卻板直接貼近 CPU、GPU 等熱源,把最難搞的「熱點」優先處理掉,其餘零組件則仍保留部分風冷。
- 浸沒式液冷(Immersion):整台伺服器浸在絕緣冷卻液中,散熱效率最高,但對維運流程、供應鏈與設備設計的衝擊也最大。
在實務上,多數資料中心會從較容易落地的直觸式液冷切入,先讓散熱能力跟上 AI 機櫃密度,再逐步把冷卻架構從「空調主導」拉向「液冷優先」。
一個常被提起的門檻是,風冷系統在 20~30 kW/櫃附近就開始進入效率遞減區,風扇與空調用電會隨熱負載急遽放大,直到 PUE 卡在 1.5 左右下不來;Rubin 世代的 AI 機櫃卻往 300 kW 甚至更高推進,這種差距已經不是多裝幾台空調就能填平。 也因此液冷對資料中心的意義不只是機房變得比較涼,而是讓同一間變電所的容量,可以支撐數倍於過去的 GPU 算力密度,把「一度電」榨出更多有用的運算結果。
液冷要規模化,必須先有一顆心臟
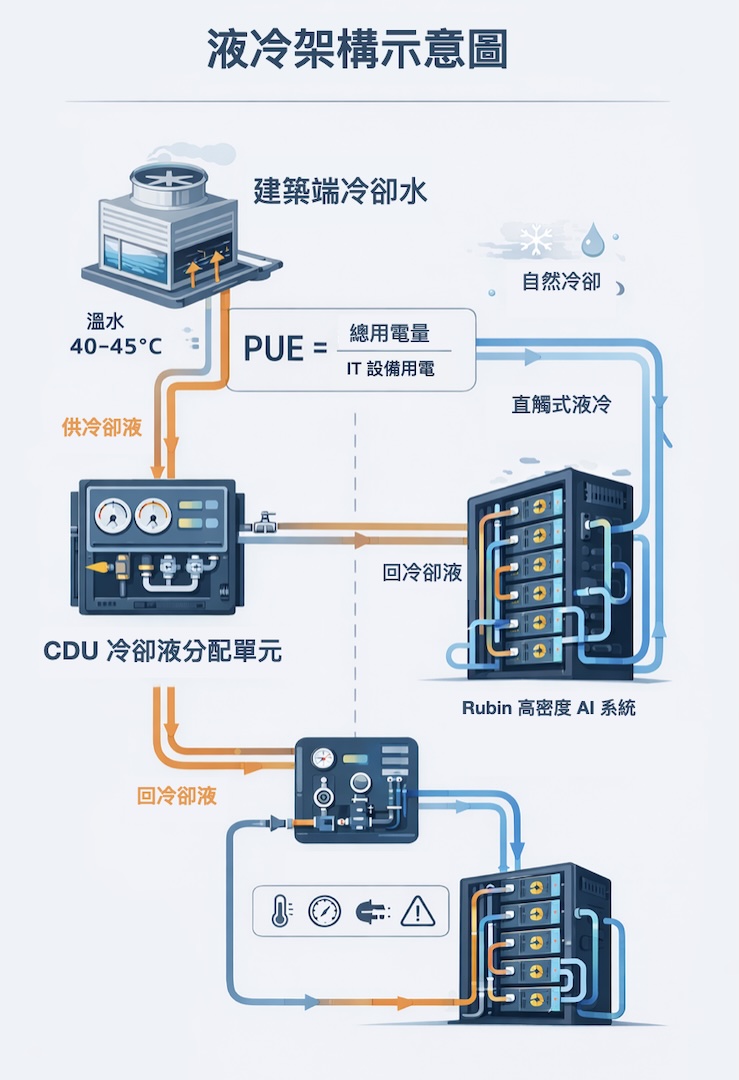
一旦導入液冷,幾乎一定會出現另一個關鍵字—CDU(Coolant Distribution Unit,冷卻液分配單元)。
你可以把 CDU 想成液冷系統的「配電箱+心臟」,一方面負責把冷卻液以合適的流量、壓力與溫度送到各個機櫃或伺服器,另一方面再把帶著熱回來的液體接住,完成熱交換與監控。
CDU 的重要性不只是有沒有液冷,而是決定液冷能不能被做成可量產、可維運、可擴充的工程系統。 液冷牽涉的不只是「多幾條水管」,還牽涉冗餘與可靠度設計(例如 N+1)、漏液偵測與風險管理、水質與腐蝕控制、壓力與流量調節,以及配合機房樓板載重與維修動線的管路規劃。
更關鍵的是,CDU 通常扮演建築端冷卻水(Facility Water System)與 IT 端冷卻液路(Technology Cooling System)之間的隔離閥與熱交換器,一方面把可能水質較差、壓力較高的建築用水隔離在外,另一方面用對 IT 更友善的配方與條件服務冷板與伺服器。 近年的 CDU 也愈來愈智慧化,透過大量感測點與控制演算法調整流量與供回水溫度,在實際案例中可以讓冷卻能耗再下降約一到兩成,進一步把 PUE 從 1.3~1.4 拉向 1.2 左右。
 (Source:科技新報整理)
(Source:科技新報整理)
換句話說,CDU 把液冷這件事從「現場客製」變成「模組化工程」,讓資料中心可以像堆積木一樣複製與擴張,而不是每一個案場都要從頭畫一次水路與控制邏輯。
Rubin 散熱帶來什麼結構性改變?
當市場開始聚焦在 Rubin 世代這一類高密度 AI 系統時,真正的變化其實不在於某一顆晶片有多熱,而在於「熱管理」開始決定整個資料中心的系統設計。 Rubin 平台被預期將單卡功耗推向 2,000 W 以上,整櫃解決方案則瞄準 300~400 kW 的熱密度,散熱再也不可能靠補風扇、加空調硬撐,而是必須從架構設計階段就以直觸式液冷、後門熱交換器甚至高溫水路為前提。
這種轉向,至少帶來三個層次的結構性改變:
從「機房空調」轉向「機櫃熱管理」
過去,冷卻設計往往以「一個機房」為單位,講究的是房間裡的溫度、氣流與冷熱通道,但 AI 熱點高度集中在少數高功耗機櫃,冷卻能力不得不貼著機櫃走。 在 Rubin 等高密度平台的機櫃裡,GPU、網路交換器甚至電源模組,都被納入同一套液路與熱管理設計,冷卻單位變成一整櫃的「算力模組」,而不是一整間房。
電力與冷卻被綁在同一張工程圖
提高機櫃功耗,意味著必須同步拉升散熱能力;反過來,散熱架構的選擇又會回頭影響整體耗電、管路設計、維運人力與擴充節奏。 Rubin 這一類高密度方向,正在逼迫資料中心把「供電模板」與「液冷模板」一起標準化——新一代機房規劃,不再只標示每櫃 30 kW 的電力上限,而是同時給出「130 kW 供電+直觸液冷+CDU 供水」的整套模組化規格。
供應鏈價值重新排序:散熱變成交付能力的一部分
在電力與上線時程成為硬指標之後,液冷(包含 CDU、熱交換器、管路與監控)不再只是一個 CAPEX 成本項目,而是決定資料中心能否「準時交付算力」的核心能力。 從傳統做機房空調與風管的設備供應商,到專門提供冷板、CDU、軟管與智慧監控的液冷廠商,誰能提供對齊 Rubin 等高密度標準的一整套方案,誰就更有機會吃下下一輪 AI 機房的資本支出。
值得一提的是,Rubin 平台本身就以溫水直觸液冷為前提設計,支援接近 40~45 ℃ 的供水溫度,讓資料中心在多數氣候條件下可以大量採用自然冷卻(free cooling),減少對冷媒壓縮機的依賴,這一點直接反映在冷卻用電與 PUE 上。 散熱不再只是配角,而是決定整體能源經濟學的主角之一。
液冷如何有效解決用電問題?
把前面的線索串起來,可以更清楚看到為什麼液冷會被視為 AI 資料中心電力問題的關鍵解法。
第一,它能降低冷卻用電的占比。相較於在高熱密度下吃力運轉的風冷系統,高比例液冷搭配智慧化 CDU,可以在相同 IT 負載下,把用於冷卻的能耗壓低一到兩成,讓整體 PUE 從 1.5 一路拉向 1.2 甚至更好。
第二,它能提高「每度電的算力產出」。當散熱跟得上,機櫃熱密度才能從 20~30 kW/櫃往 100 kW、甚至 300 kW/櫃前進,在同樣的供電容量下塞進更多 GPU,實際吞吐的 AI 模型推論與訓練工作量自然跟著翻倍。
第三,它能把很多原本難以掌控的不確定性變成可預期的工程條件。透過 CDU 與液路模組化,把壓力、流量、水質與冗餘做成標準件,未來擴充機櫃或導入新一代像 Rubin 這樣的高密度平台時,資料中心不必每次重頭來過,導入時程與上線節奏會更可預測。
換句話說,AI 資料中心的電力戰場不只停留在「誰搶到電」,而是進一步競賽「誰能把有限的電用得更值」。 當供電條件成為選址的第一關,下一輪的關鍵差異,就會落在誰能用更成熟的液冷與熱管理,把有限電力轉換成更高密度、更快交付、也更具能源效率的算力。
(首圖來源:AI 生成)





